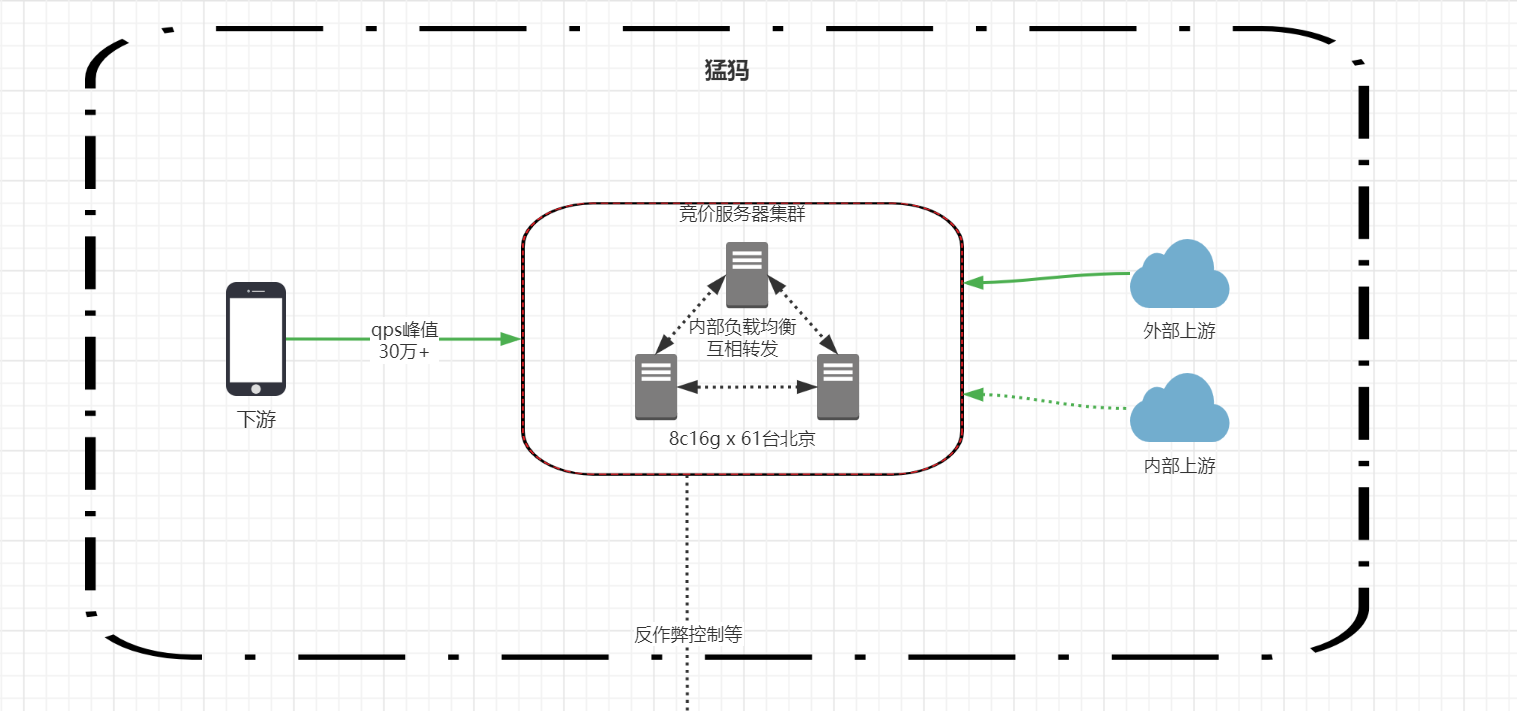
背景
我负责的某个项目,一到晚上流量大的时间段,客户反映超时严重上涨
问题排查:
1.进入其中一个项目节点,查看代码是否有报错
2.去阿里云后台查看 CPU/内存 是否满了
3.查看阿里云其他指标维度是否异常
问题确认:
对比阿里云后台查看,超时的时间段ECS连接数暴涨
问题解决思路:
1.代码层面:
a.首先想到的是,是不是nginx长链接设置的有问题
b.排查上下游流量,是否不支持http1.1协议(ps:因为http1.0默认是不支持keepalive)
c.借助 iftop/netstat 网络工具排查
2.服务器层面:
a.根据项目特点,尝试优化内核
b.升级服务器资源
过程:
1.代码层面
a.经过几个晚上优化 长链接数、长链接超时时间 无明显变化
b.多次抽样排查都是http1.1
c.待描述
2.服务器层面
a.同样优化长链接无变化(借鉴https://developer.aliyun.com/article/514389)
b.暂不考虑此方案(考虑到成本 + 感觉治标不治本)
重点来了:使用netstat分析
超时时间段:
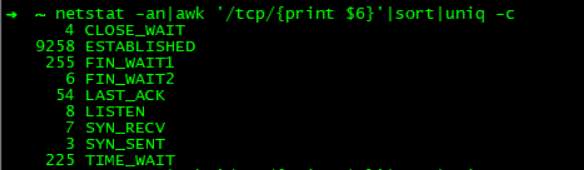
平常正常时间段:
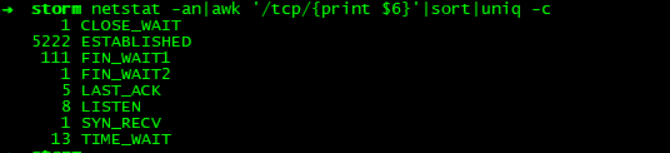
在晚上超时时间段复现出ESTABLISHED是平时的2倍
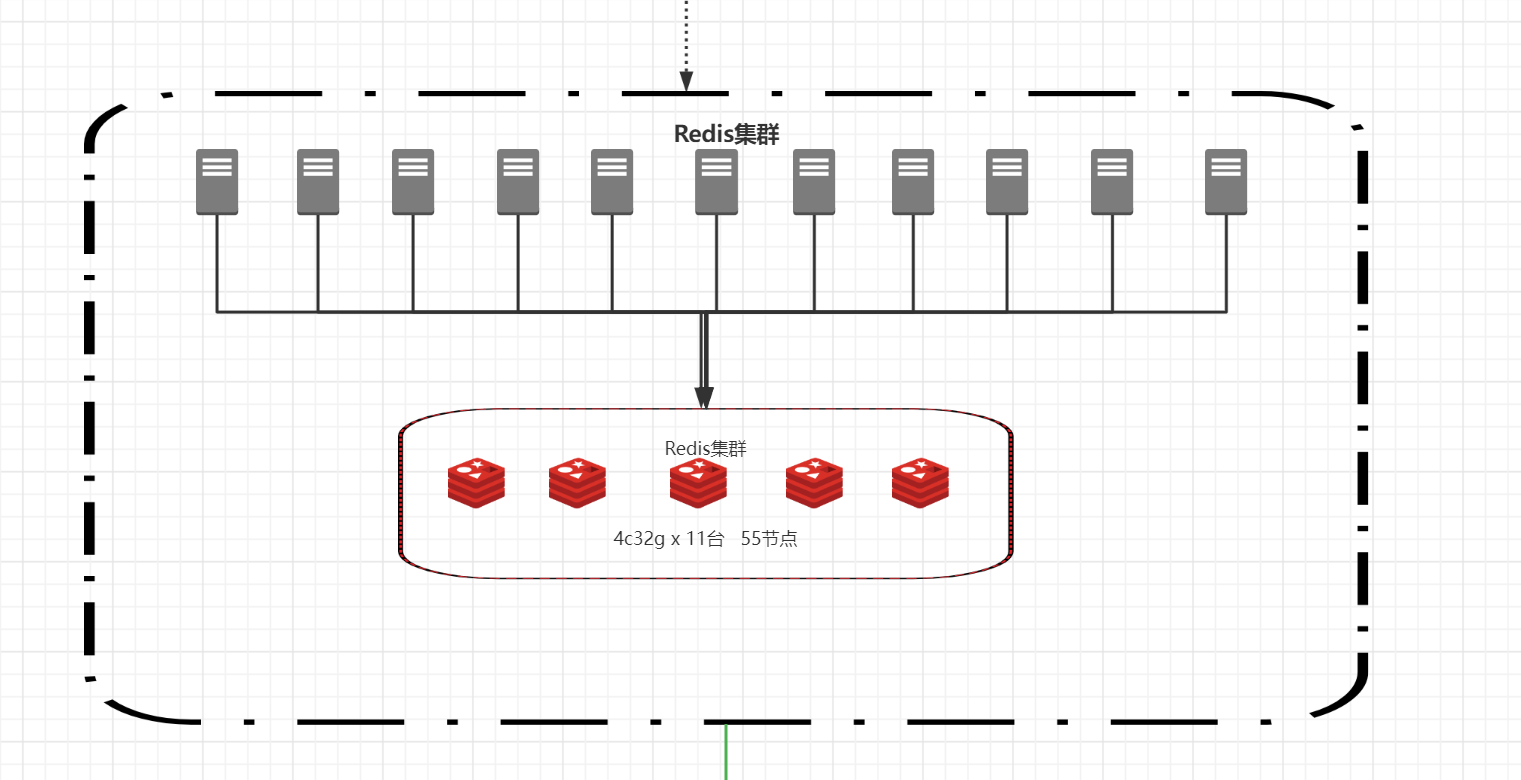
然后通过ESTABLISHED查出对应的ip是内部redis集群中的某个节点,去阿里云后台查看redis负载了(没有设置预警),查看对应redis esc链接数已经跑到100k了

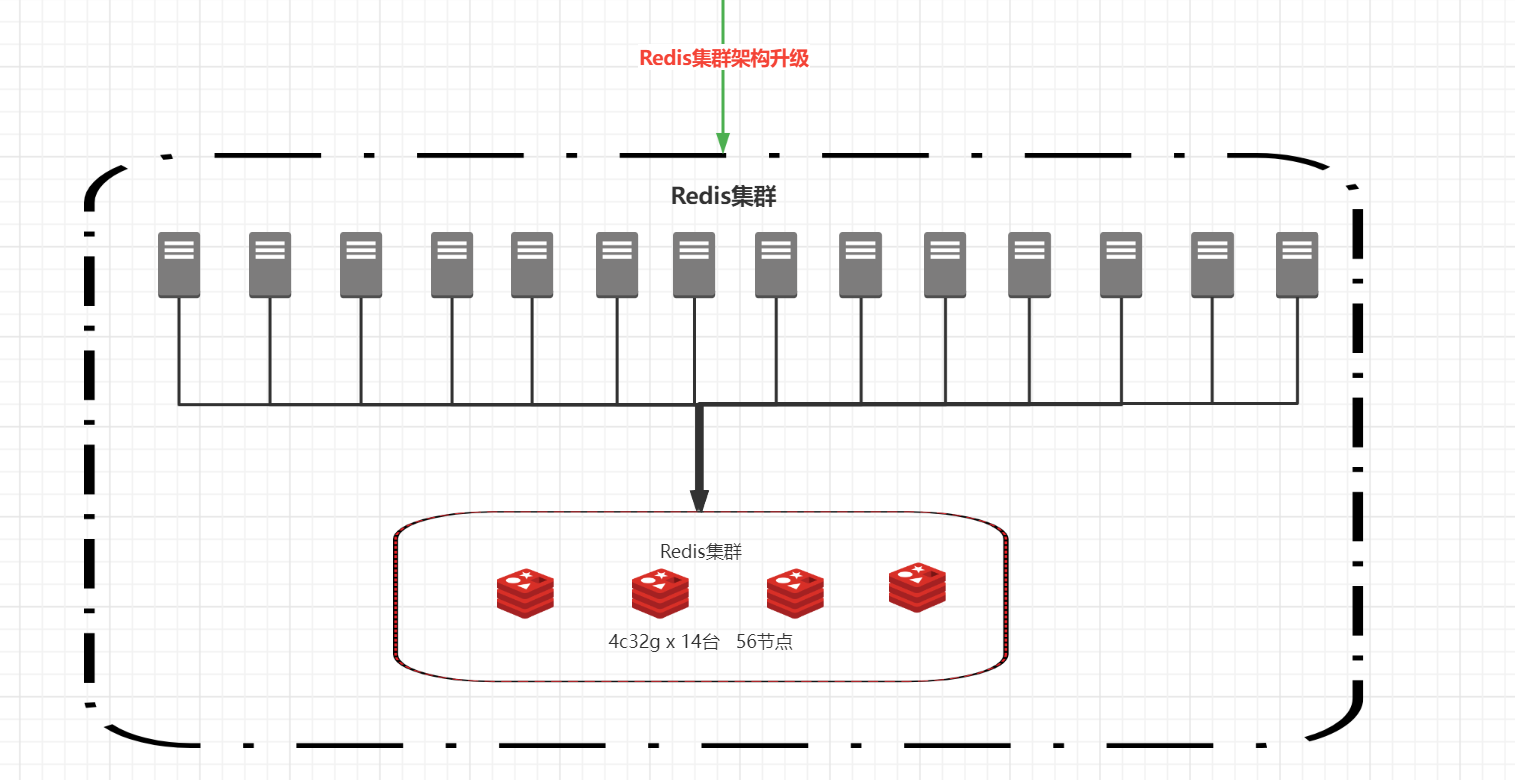
解决方案:减少redis负载 + 加redis节点
架构升级如下: